9.7 KiB
napkin-text-analysis
![]()
Napkin is a Python tool to produce statistical analysis of a text.
Analysis features are :
- Verbs frequency
- Nouns frequency
- Digit frequency
- Labels frequency such as (Person, organisation, product, location) as defined in spacy.io named entities
- URL frequency
- Email frequency
- Mention frequency (everything prefixed with an @ symbol)
- Out-Of-Vocabulary (OOV) word frequency meaning any words outside English dictionary
Verbs and nouns are in their lemmatized form by default but the option --verbatim allows to keep the original inflection.
Intermediate results are stored in a Redis database to allow the analysis of multiple text files.
requirements
- Python >= 3.6
- spacy.io
- redis (a redis server running on port 6380 is required)
- pycld3
- tabulate
how to use napkin
usage: napkin.py [-h] [-v V] [-f F] [-t T] [-s] [-o O] [-l L] [--verbatim]
[--no-flushdb] [--binary] [--analysis ANALYSIS]
[--disable-parser] [--disable-tagger]
[--token-span TOKEN_SPAN]
Extract statistical analysis of text
optional arguments:
-h, --help show this help message and exit
-v V verbose output
-f F file to analyse
-t T maximum value for the top list (default is 100) -1 is
no limit
-s display the overall statistics (default is False)
-o O output format (default is csv), json, readable
-l L language used for the analysis (default is en)
--verbatim Don't use the lemmatized form, use verbatim. (default
is the lematized form)
--no-flushdb Don't flush the redisdb, useful when you want to
process multiple files and aggregate the results. (by
default the redis database is flushed at each run)
--binary set output in binary instead of UTF-8 (default)
--analysis ANALYSIS Limit output to a specific analysis (verb, noun,
hashtag, mention, digit, url, oov, labels, punct).
(Default is all analysis are displayed)
--disable-parser disable parser component in Spacy
--disable-tagger disable tagger component in Spacy
--token-span TOKEN_SPAN
Find the sentences where a specific token is located
example usage of napkin
Generate all analysis for a given text
A sample file "The Prince, by Nicoló Machiavelli" is included to test napkin.
python3 ./bin/napkin.py -o readable -f samples/the-prince.txt -t 4
Example output:
╒═════════════════╕
│ Top 4 of verb │
╞═════════════════╡
│ 116 occurences │
├─────────────────┤
│ make │
├─────────────────┤
│ 106 occurences │
├─────────────────┤
│ may │
├─────────────────┤
│ 102 occurences │
├─────────────────┤
│ would │
╘═════════════════╛
╒═════════════════╕
│ Top 4 of noun │
╞═════════════════╡
│ 108 occurences │
├─────────────────┤
│ state │
├─────────────────┤
│ 90 occurences │
├─────────────────┤
│ people │
├─────────────────┤
│ one │
╘═════════════════╛
╒════════════════════╕
│ Top 4 of hashtag │
╞════════════════════╡
╘════════════════════╛
╒════════════════════╕
│ Top 4 of mention │
╞════════════════════╡
╘════════════════════╛
╒══════════════════╕
│ Top 4 of digit │
╞══════════════════╡
│ 750175 │
├──────────────────┤
│ 6221541 │
├──────────────────┤
│ 57037 │
╘══════════════════╛
╒═════════════════════════════════════════╕
│ Top 4 of url │
╞═════════════════════════════════════════╡
│ 1 occurences │
├─────────────────────────────────────────┤
│ www.gutenberg.org/license │
├─────────────────────────────────────────┤
│ www.gutenberg.org/contact │
├─────────────────────────────────────────┤
│ http://www.gutenberg.org/5/7/0/3/57037/ │
╘═════════════════════════════════════════╛
╒════════════════╕
│ Top 4 of oov │
╞════════════════╡
│ 6 occurences │
├────────────────┤
│ Vitelli │
├────────────────┤
│ Pertinax │
├────────────────┤
│ Orsinis │
╘════════════════╛
╒═══════════════════╕
│ Top 4 of labels │
╞═══════════════════╡
│ 197 occurences │
├───────────────────┤
│ CARDINAL │
├───────────────────┤
│ 189 occurences │
├───────────────────┤
│ ORG │
├───────────────────┤
│ 131 occurences │
├───────────────────┤
│ NORP │
╘═══════════════════╛
Extract the sentences associated to a specific token
python3 ./bin/napkin.py -o readable -f samples/the-prince.txt -t 4 --token-span "Vitelli"
╒════════════════════════════════════════════════════════════════════════╕
│ Top 4 of span │
╞════════════════════════════════════════════════════════════════════════╡
│ Nevertheless, Messer Niccolo Vitelli has been seen in │
│ our own time to destroy two fortresses in Città di Castello in order │
│ to keep that state. │
├────────────────────────────────────────────────────────────────────────┤
│ And the │
│ difference between these forces can be easily seen if one considers │
│ the difference between the reputation of the duke when he had only the │
│ French, when he had the Orsini and Vitelli, and when he had to rely │
│ on himself and his own soldiers. │
├────────────────────────────────────────────────────────────────────────┤
│ And that his foundations were │
│ good is seen from the fact that the Romagna waited for him more than a │
│ month; in Rome, although half dead, he remained secure, and although │
│ the Baglioni, Vitelli, and Orsini entered Rome they found no followers │
│ against him. │
╘════════════════════════════════════════════════════════════════════════╛
overview of processing in napkin
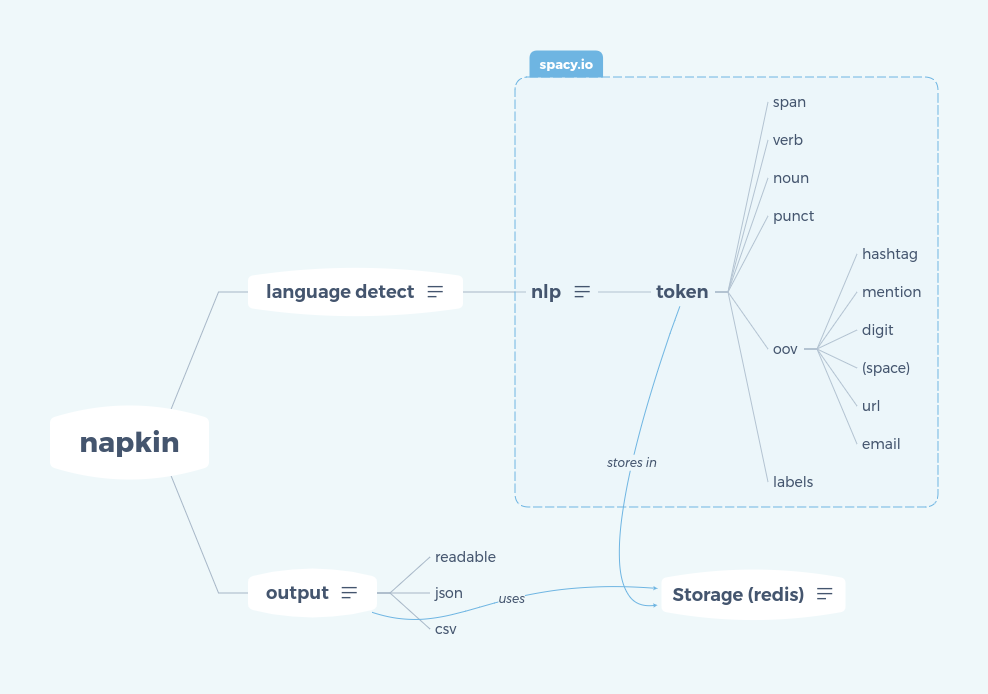
what about the name?
The name 'napkin' came after a first sketch of the idea on a napkin. The goal was also to provide a simple text analysis tool which can be run on the corner of table in a kitchen.
LICENSE
napkin is free software under the AGPLv3 license.
Copyright (C) 2020 Alexandre Dulaunoy
Copyright (C) 2020 Pauline Bourmeau